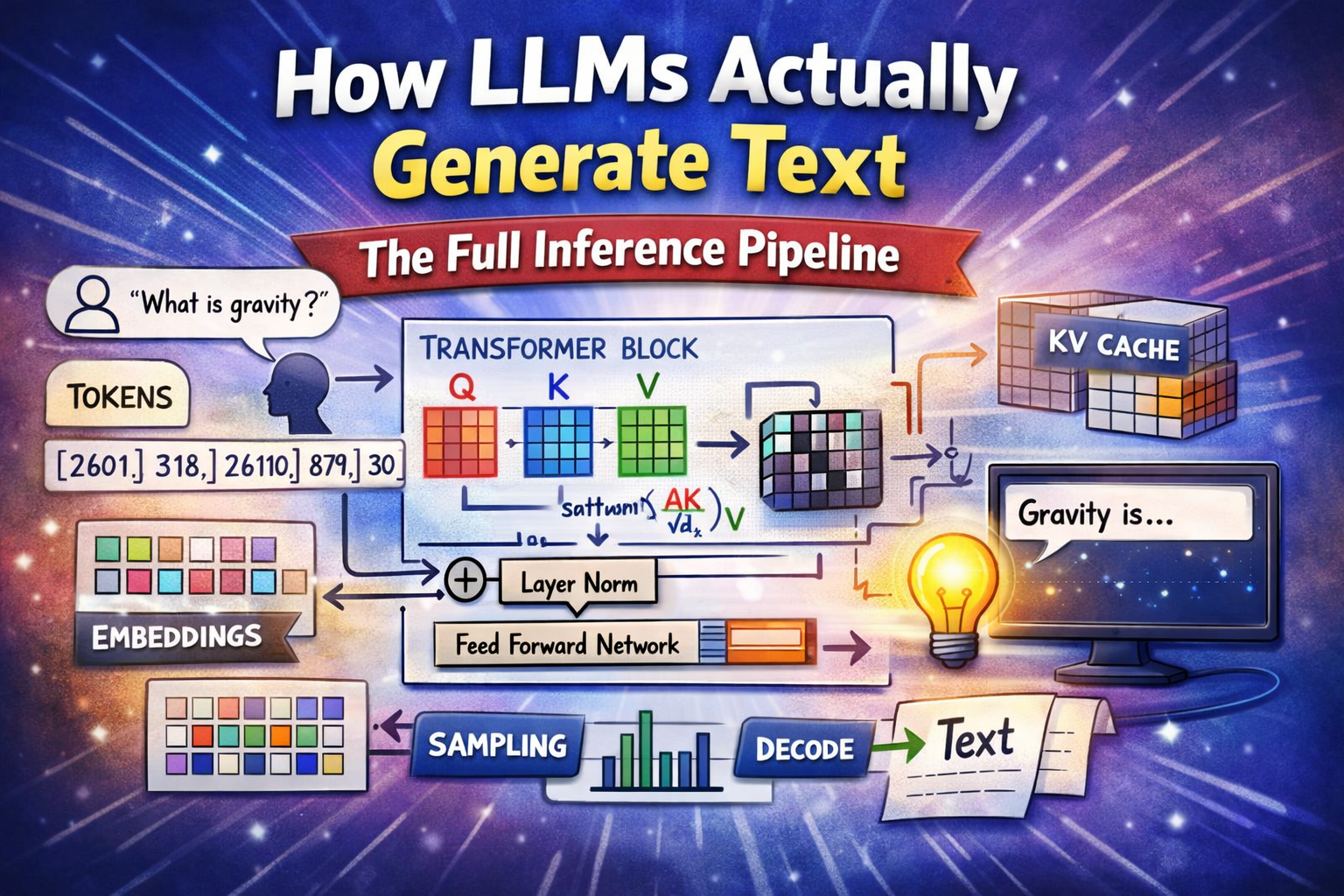
How LLMs Actually Generate Text ? The Full Inference Pipeline
You type a simple question like ?What is gravity?? and within seconds, you get a clean, structured answer.
To most people, it feels instant. Almost magical.
But under the hood, that response is the result of a highly optimized pipeline involving tokenization, mathematical transformations, probability distributions, and memory management.
If you?re serious about using AI?not just consuming it?understanding this pipeline gives you a major advantage.
Step 1: Input ? Where Everything Begins
Every interaction with an LLM starts with raw text input. This could be a question, a command, or even a paragraph of context.
What is gravity?
At this stage, the model hasn?t ?understood? anything yet. It simply receives a string of characters.
---Step 2: Tokenization ? Breaking Text into Pieces
Large language models don?t process full words. Instead, they break text into smaller units called tokens.
Tokens: What | is | grav | ity | ?
Token IDs: [2601, 318, 26110, 879, 30]
This approach allows the model to handle a massive vocabulary efficiently. For example, ?gravity? might be split into ?grav? and ?ity,? enabling the model to reuse patterns across different words.
This is also why unusual or misspelled words can still be understood?the model is working with subword units, not entire words.
---Step 3: Embedding Layer ? Turning Words into Numbers
Once tokenized, each token is converted into a numerical representation called an embedding.
d_model = 4096
Embedding Matrix: (sequence length ? 4096)
Each token becomes a high-dimensional vector that captures meaning, relationships, and context.
This is where language starts becoming math.
Words that are similar in meaning end up closer together in this vector space, allowing the model to reason about relationships like synonyms, categories, and context.
---Step 4: Transformer Block ? The Brain of the Model
This is where the real computation happens.
The transformer processes embeddings through multiple layers?often dozens or even close to 100 in advanced models.
softmax(QK? / ?d?) ? V
This mechanism is called self-attention, and it allows the model to determine how important each word is relative to others in the sentence.
For example, in the sentence ?The cat sat on the mat,? attention helps the model understand relationships between ?cat? and ?sat.?
Feed-Forward Network
After attention, each token passes through a feed-forward neural network:
Linear ? ReLU / SwiGLU ? Linear
This step refines the representation further, adding non-linearity and improving the model?s ability to capture complex patterns.
KV Cache ? The Hidden Performance Trick
The model stores previously computed key (K) and value (V) pairs in memory.
This avoids recomputing attention for earlier tokens, significantly improving performance during generation.
However, this cache grows with sequence length?making it a major memory bottleneck.
---Step 5: Linear + Softmax ? Predicting the Next Token
After passing through all transformer layers, the model projects the final representation into a probability distribution over its vocabulary.
Linear ? logits (~128K tokens)
Softmax ? probabilities
Each possible next token gets a probability score.
The model doesn?t ?choose a sentence??it predicts one token at a time.
---Step 6: Sampling ? Choosing What Comes Next
This is where things get interesting.
Instead of always picking the most likely token, different strategies are used:
- Greedy: Always pick the highest probability
- Top-K: Sample from top K options
- Top-P: Sample from a probability threshold
- Temperature: Controls randomness
Lower temperature = more predictable Higher temperature = more creative
This is why AI responses can vary even with the same input.
---Step 7: Speculative Decoding ? Speed Optimization
Modern systems use a clever trick to speed things up.
A smaller ?draft? model generates multiple tokens quickly, while the larger model verifies them in parallel.
Draft: Grav | ity | is | a
Verified: accept / reject
This reduces latency significantly without sacrificing quality.
---Step 8: Detokenization ? Back to Human Language
Once tokens are generated, they are converted back into readable text.
"Gravity is a fundamental force..."
This step reconstructs natural language from token IDs.
---Step 9: Streaming Output ? Why Responses Appear Gradually
You don?t receive the full response at once.
Instead, tokens are streamed one by one.
This is why answers appear progressively in chat interfaces.
---What Most People Completely Miss
- Prefill Phase: Processes input tokens in parallel (compute-heavy)
- Decode Phase: Generates tokens sequentially (memory-heavy)
- KV Cache: Main bottleneck as sequences grow
- FlashAttention: Reduces memory bandwidth usage
- Quantization: Cuts memory usage by up to 4?
These optimizations are the reason modern AI systems can scale.
---Why This Matters (And Why You Should Care)
A 70-billion parameter model can require over 140GB of GPU memory in full precision.
Without optimization techniques like quantization and caching, these systems would be impractical.
But beyond the technical side, understanding this pipeline changes how you use AI:
- You write better prompts
- You debug outputs more effectively
- You design smarter AI systems
Most users treat AI like a black box.
The ones who understand it? They get leverage.
---Final Thought
LLMs are not magic. They are highly optimized prediction engines operating at scale.
And once you understand how they work, you stop guessing?and start controlling the output.




💬 0 Comments
+ Leave a comment